Volcano is een project van de Cloud Native Computing Foundation (CNCF) dat vooral wordt gebruikt als batch systeem op het gebied van AI en voor Big Data toepassingen wanneer de omgeving is gebouwd op Kubernetes.
Het CNCF project Volcano is een batch systeem gebouwd op Kubernetes. De focus van de workloads ligt vooral op workloads op het gebied van AI (machine learning/deep learning) en andere Big Data-toepassingen die een hoge rekenbelasting veroorzaken en optimaal moeten worden ingepland in het Kubernetes-cluster.
Frameworks zoals “Tensorflow”, “Spark”, “Pytorch”, “MPI”, “Flink”, “Argo”, “Mindspore” en “PaddlePaddle” die workloads met een hoge werklast vereisen, werken goed met Volcano. Volcano ondersteunt integratie met verschillende rekenframeworks, bijvoorbeeld “Kubeflow” en “Kubegene”.
Volcano breidt Kubernetes uit met verschillende functies. Deze omvatten hoofdzakelijk scheduling extensions, job management extensions en accelerators zoals GPU en FPGA.
Gegroepeerde planning voor containers
Volcano is een van de projecten die zijn voortgekomen uit “Kube Batch”. Het project werd oorspronkelijk opgezet om containers beter te groeperen en middelen beter te plannen.
Speciaal voor AI- en Big Data-oplossingen is Volcano in Kubernetes-clusters een belangrijk onderdeel voor een betere benutting van resources. Met Volcano is het mogelijk om AI-workloads in Kubernetes-clusters aanzienlijk te versnellen.
Origineel geaccepteerd door CNCF in 2015 als een sandboxed ‘Kubernetes-native system for high-performance workloads’-project, kreeg het in 2019 de Volcano-aanduiding. De broncode en issues van het project zijn ook te vinden op Github.
Toevoeging voor Kubernetes scheduler
De scheduler in Kubernetes plant containers één voor één. Dit is nuttig voor veel scenario’s, maar zelden voor werklasten met rekenintensieve taken. Vooral bij het trainen van AI-omgevingen en ook bij Big Data-analyses spelen hele groepen containers vaak een belangrijke rol.
Als een toepassing meerdere containers nodig heeft voor de uitvoering ervan, kan het met de standaardplanner in Kubernetes, veroorzaakt door enkelvoudige scheduling, gebeuren dat individuele containers van de groep niet kunnen starten omdat er niet genoeg resources beschikbaar zijn. Het gevolg is dat dergelijke werklasten minder goed of helemaal niet werken.
Gelijktijdig veroorzaken de reeds gestarte containers van de groep echter bronnen die van geen enkel nut zijn, omdat een essentieel onderdeel van de groep ontbreekt. Dit is de aanpak van Volcano. De oplossing combineert de hele groep van onderling afhankelijke containers en plant hun middelen samen.
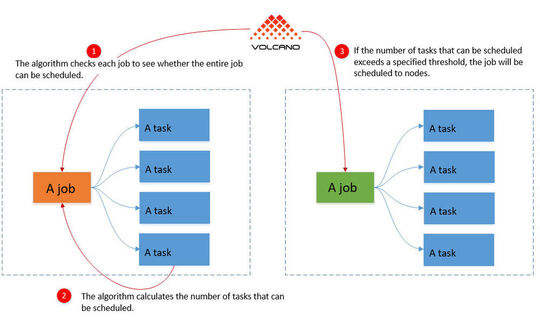
Als alle containers in de groep niet kunnen starten, voorkomt Volcano dat alle containers in de groep kunnen starten. Dit vermindert de belasting van het Kubernetes cluster aanzienlijk, omdat er in dit geval in ieder geval resources beschikbaar zijn voor andere containers en containergroepen. Als er meerdere van dergelijke groepen in een cluster draaien, is het gebruik van Volcano volkomen logisch.
Automatische toewijzing van resources voor containers
Volcano heeft via zijn interne functies een volledig overzicht van de individuele containers op Kubernetes, maar ook van groepen containers die gezamenlijk voor een workload zorgen. Naast het groeperen en delen van resources tussen containers, kan de software ook bepalen welke nodes het meest geschikt zijn om de individuele containers in een groep te bevoorraden.
De CPU, het geheugen, de GPU en andere resources kunnen ook specifiek worden gepland en beschikbaar worden gesteld aan de containers van een groep. Volcano kent de vrije bronnen en de maximale belasting van alle knooppunten. Op basis van deze informatie selecteert Volcano het meest geschikte knooppunt voor elke container.
Volcano biedt ook de mogelijkheid om met prioriteiten te werken. Functies zoals Domain Resource Fairness (DRF) en Binpack zijn ook in Volcano geïntegreerd en kunnen bij de resourceplanning in aanmerking worden genomen. Als verschillende groepen met elkaar concurreren of niet samen op één node mogen worden gebruikt, kan hier met Volcano rekening mee worden gehouden.
Hoe Volcano werkt
Domain Resource Fairness (DRF) kan prioriteit geven aan taken, zelfs in YARN en Mesos. DRF kan bijvoorbeeld ook prioriteit geven aan taken waarvoor minder middelen nodig zijn. Hierdoor kan het cluster meer taken uitvoeren en worden kleine taken niet geblokkeerd door grote toepassingen. In Volcano definieert DRF een taak als het geheel van alle noodzakelijke containers voor een gedefinieerde taak.
Het binpack-algoritme probeert zoveel mogelijk gebruik te maken van alle knooppunten in het cluster. Configuraties kunnen zo worden gemaakt dat knooppunten eerst volledig bezet zijn voordat Volcano verdere knooppunten bezet. Binpack plant het gebruik van alle nodes in het cluster en plant vervolgens de individuele jobs volgens deze specificaties.
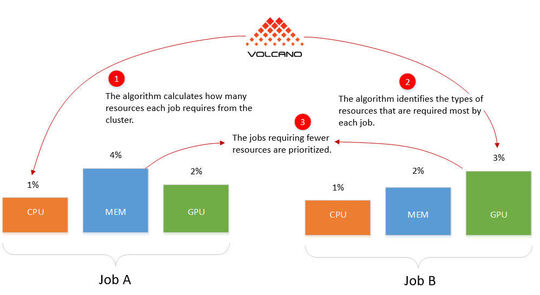
Het wachtrijalgoritme kan de volledige toewijzing van hulpbronnen van een cluster regelen. Deze techniek wordt ook gebruikt in YARN. Als meerdere containergroepen een pool van bronnen delen in een cluster, kan Volcano controleren welke groep meer bronnen nodig heeft.
Op deze manier herkent Volcano in een dergelijk scenario ook welke groep waarschijnlijk minder hulpbronnen gebruikt en kan deze groep als eerste worden uitgevoerd. Zodra hun taken zijn voltooid, kan Volcano de groep met de hogere resource load inplannen. Volcano kan zijn verschillende scheduling algoritme plug-ins verschillend wegen.
Ergo: Als op een Kubernetes-cluster workloads worden gebruikt die zijn gebaseerd op meerdere containers en pods en een hoog resourceverbruik hebben, kan Volcano aanzienlijke voordelen opleveren. Het gebruik ervan is vooral zinvol bij het werken met AI-workloads, bijvoorbeeld voor machinaal leren en diep leren. Maar ook andere workloads met veel resources op het gebied van Big Data voor rendering en uitgebreide berekeningen profiteren van Volcano.
Ten slotte biedt Volcano ook voordelen voor de andere workloads in het cluster, omdat de veel betere resource scheduling betekent dat de andere workloads ook meer resources kunnen gebruiken of bij het opstarten voorrang krijgen omdat ze minder resources nodig hebben en dus sneller klaar zijn met hun werk.
* De auteur Thomas Joos is IT-consultant en schrijft technische boeken en artikelen. Op DataCenter-Insider vult hij zijn eigen blog met tips en trucs voor admins. “Tom’s Admin Blog”.